Переезд
Изначально было опубликовано в моем medium блоге.
В декабре 2017 мы решили сменить датацентр (ДЦ). Решение серьезное и принималось из-за 2х причин. Отсутствие защиты от DDoS атак и ценник. Про то как классно ДЦ нам помог(нет) во время атаки я уже рассказывал, ну и снизить затраты на инфраструктуру не потеряв в производительности это challenge.
Важные решения в компании не принимаются одним человеком и должны быть хорошо аргументированы.
Как защищал решение перед руководством
1. Провел исследование нескольких вендоров
2. Составил таблицу +/- нового вендора
3. Посчитал новую стоимость владения (TCO — Total Cost of Ownership)
4. Посчитал стоимость переезда. Это человеко-часы, возможный простой по другим задачам, риски на частичную потерю работоспособности системы или полный выход из строя системы
5. Составил план переезда
5. Оформил вышеперечисленные пункты в набор слов и таблиц Excel
6. Написал письмо на всех заинтересованных
На что обращают внимание:
- CFO — профит/потерю в деньгах
- CEO — репутационные риски из-за простоя системы, как простой по другим задачам затронет бизнес в целом, целесообразность переезда именно сейчас
Как выбрать ДЦ
В моем случае всё было достаточно просто, потому что у нас уже была часть инфраструктуры в этом ДЦ. Но сравнения с другими хостингам мы с системным администратором тем не менее проводили.
Приоритеты в списке расставьте сами:
- Географическое расположение. Чем ближе, тем лучше, но не Россия 😏
- Стоимость оборудования. Дешево, не всегда хорошо, нужно смотреть на характеристики.
- Характеристики оборудования. Дата выпуска процессоров, их частота. Объем оперативной памяти и возможность для расширения. SSD/HDD, возможность RAID с батарейкой, сетевые карты и входящий канал (10Gb/s — отлично, 1Gb/s — пойдет).
- Функционал по настройке сети. В Softlayer можно сделать хороший LVS и утилизировать по факту канал каждого сервера, получая 1xN Gb/s (где N — кол-во серверов). В Hetzner IP прибит к серверу и с другой машины отвечать нельзя. Failover IP перемещается только через запрос в API.
- Защита от DDoS. Да, в 2018 без неё никуда, особенно если вы интернет издание. Есть конечно бесплатные CloudFlare и Google Shield, но вы теряете в контроле. Если ДЦ может защитить вас на сетевых уровнях, то лучше выбрать такой ДЦ.
- Включенный в пакет сетевой трафик. Оборудование быстро устаревает, а за трафик в последняя время берут дорого. Чем больше в базовом пакете, тем лучше.
- Наличие русскоговорящей поддержки. Да, на англ можно спокойно всё узнать, но налаженный контакт с менеджером в ДЦ намного полезнее. Можно узнать много подробностей и получить хорошую консультацию о том как на их мощностях построить нужную инфраструктуру.
- Облачные сервисы. У нас есть Ceph для хранения изображений, если бы похожее решение as a service было у ДЦ, то я думаю взял бы. Но пока поддерживаем сами.
- Выделенный канал с другими ДЦ. Как правило большие ребята прокидывают свои кабели или выкупают мощность, чтобы дать крупным клиентам возможность перекидывать большие объемы данных между разными провайдерам.
После этапа согласований можно приступить к переезду. Описываю личный опыт:
1. Заказали машины нужной конфигурации. Обычно 3 рабочих дня, но в этот раз делали неделю, списываю на нестандартный запрос (RAID с батарейкой, дополнительные сетевые, failover IP, дополнительная подсеть).
2. Засетапили инфраструктуру. Образы виртуальных машин, настройка сетевых интерфейсов, балансировка, небольшие тесты железа. (1,5–2 недели)
3. Подготовка проектов к переезду. К этому моменту должны быть известны подсети, отказоустойчивые адреса для сервисов и оттестированы failover. (2 дня)
4. Зафиксировали план переезда. Это просто последовательность действий, чтобы во время работ не задумываться о следующем шаге и ничего не забыть.
5. Согласовали дату и временное окно. Сотрудники не ходят в приложения и ничего не создают, чтобы избежать лишних проблем. Мы пока не Google и даже не VK, поэтому можем себе позволить.
Как выглядит сам переезд
Что у вас должно быть на старте:
- Набор серых IP всех виртуальных машин
- Набор highly available IP для инфраструктурных сервисов (Memcached, DB, Elastic, LoadBalancer, etc)
- VPN туннели между ДЦ
- Набор конфигов приложений с новыми адресами
- Список команд для старта/стопа приложений/очередей/сервисов под рукой
- Холодная голова и запас времени
Cache. У нас свой небольшой CDN и чтобы вал запросов не положил хранилище статики, добавили новый IP на балансер с меньшим чем у основных машин весом и дали кэшу прогреться. После стабильных 90% Cache hit, переключаем весь трафик на новые машины.
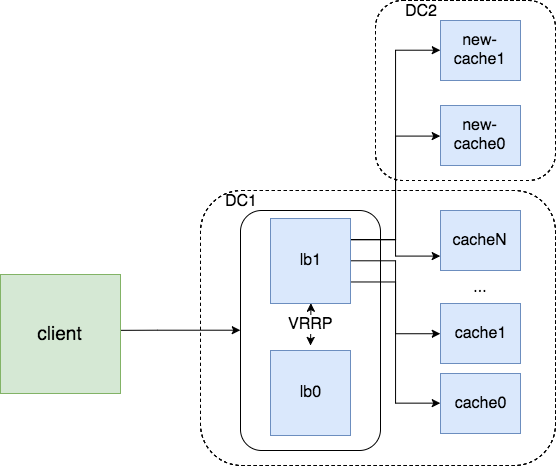
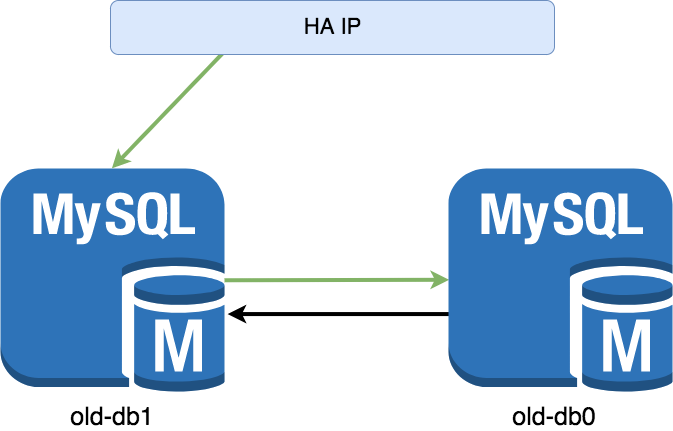
DB. Master-Master репликация с одни активным мастером. Исходная позиция old-db0<->old-db1. Приложения смотрят HA IP –> old-db1.
Делаем read replica new-db1 и new-db0. Приходим к виду newdb0<-new-db1<-old-db1<->old-db0. Это схему надо настроить заранее, чтобы реплики успели подтянуть данные.
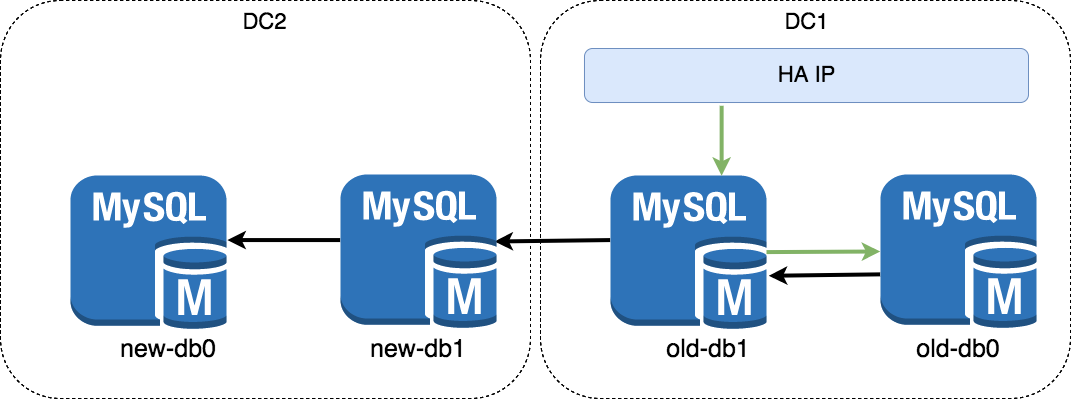
Рвем мастер-мастер old-db0<->old-db1, настраиваем новый master-master old-db1<->new-db1. Переходим к приложениям.
Поднимаем приложения на новых машинах. Новые инстансы смотрят в HA IP –> new-db1. Очереди не поднимаем, записи в базу пока нет. Проверяем работоспособность. Прогреваем кэш несколькими запросами.
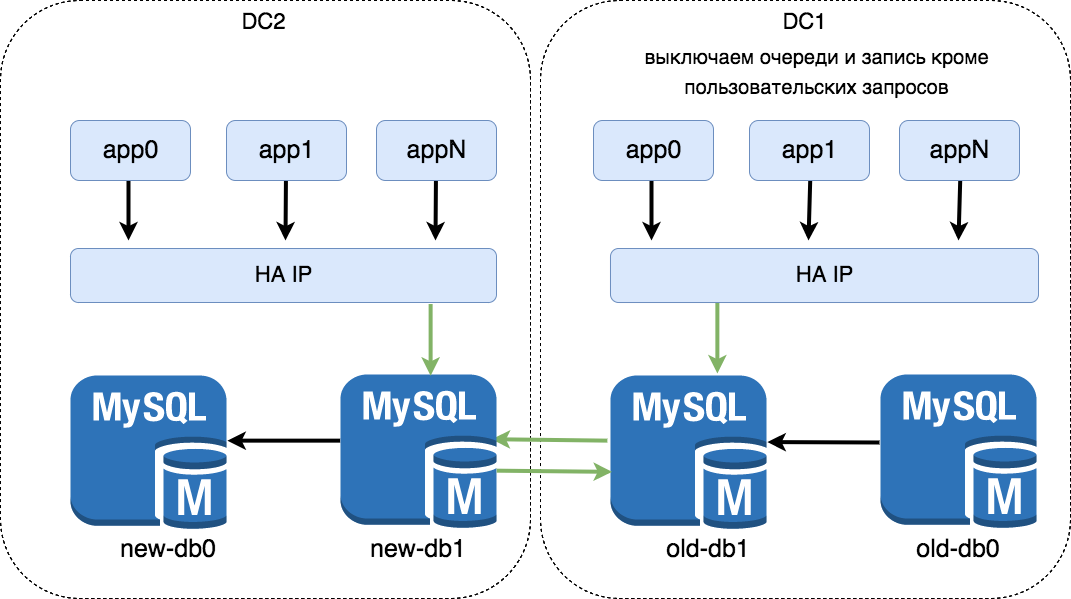
На старых машинах выключаем очереди и всё что может писать в базу, кроме пользовательских запросов. Делаем проксирование запросов в новый DC на nginx. Переключаем DNS. Ускоряем обновление публичных DNS через волшебную кнопку Google.
Выключаем приложения на старых машинах, проверяем наличие коннектов на old-db1. Когда кроме процессов репликации ничего нет, идем рвать мастер-мастер. Делаем новый мастер-мастер new-db1<–>new-db0. Рвем связь со старой базой в DC1.
Включаем очереди и дополнительные сервисы. Запускаем переиндексацию документов в Elastic. Можно было бы перетащить базу и доиндексировать, но данных немного, поэтому решили сделать переиндекс для профилактики. Elastic только для поиска, а он исторически делает <1% трафика, поэтому не страшно выдать пользоветлям пустой ответ.
Делаем ручные проверки критичных мест приложений. Если что-то идет не так, то чиним, но у нас было ок.
У изданий была куча дополнительных доменов, нужно переключить все. Что именно можно найти в конфигах nginx в разделе server –> server_name.
Проверяем все правила алертов мониторинга и идем отдыхать.
Спустя 2 дня, когда DNS обновились, начинаем тушить машины в старом ДЦ и запрашиваем их выключение.
В итоге мы получили снижение стоимости владения в 4 раза, но потеряли в кол-ве процессоров.